【版本】
当前版本号v20250303
| 版本 | 修改说明 |
|---|---|
| v20250303 | 加入关闭防火墙操作,增加常见问题 |
| v20250211 | 初始化版本 |
任务1.1 部署 Hadoop 完全分布式
【任务目的】
- 掌握搭建 Hadoop 完全分布模式环境。
- 熟练掌握 Linux 常用命令如vi、ping、cat、ssh等。
- 掌握VirtualBox、FinalShell等客户端的使用。
【任务环境】
- 内存:至少4G
- 硬盘:至少空余40G
- 操作系统: 64位 Windows系统。
【任务资源】
- FinalShell
- CentOS 7.9系统镜像
- VirtualBox 7
- Hadoop 3 安装包
【任务要求】
- (1)完成模板机的克隆
- (2)完成Hadoop 完全分布模式的部署
【任务说明】
- (1)由于部署 Hadoop 完全分布式需要3个节点,我们使用虚拟化技术,在本地虚拟化出3台虚拟机来部署 Hadoop 完全分布式环境。
- (2)对于 Hadoop 平台的编程调用,需要准备好 Java 的标准开发环境。我们使用 Java 开发常见的 JDK+Maven+IDEA 组合来进行部署和配置。
【任务步骤】
安装 VirtualBox
- 安装 VirtualBox ,过程略。如果之前有安装旧版本的 VirtualBox,请先卸载。
导入模板机
解压虚拟机压缩包
HadoopTmpl.zip到本地目录路径,例如D:\VirtualBoxImages。注意这个路径不能含有中文或者空格。解压以后可以看到以下文件。
打开 VirtualBox ,并导入前面解压的“HadoopTmpl”虚拟机,由于接下来我们要从这台虚拟机复制出3台新的虚拟机,所以我们称这台机为“模板机”。
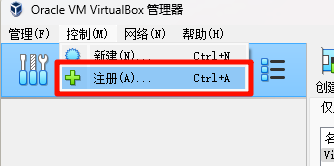
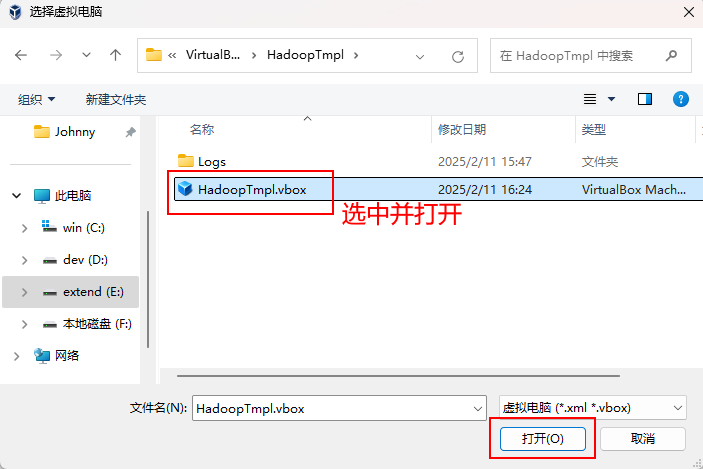
导入成功以后可以在 VirtualBox 左侧看到
HadoopTmpl虚拟机。
配置模板机
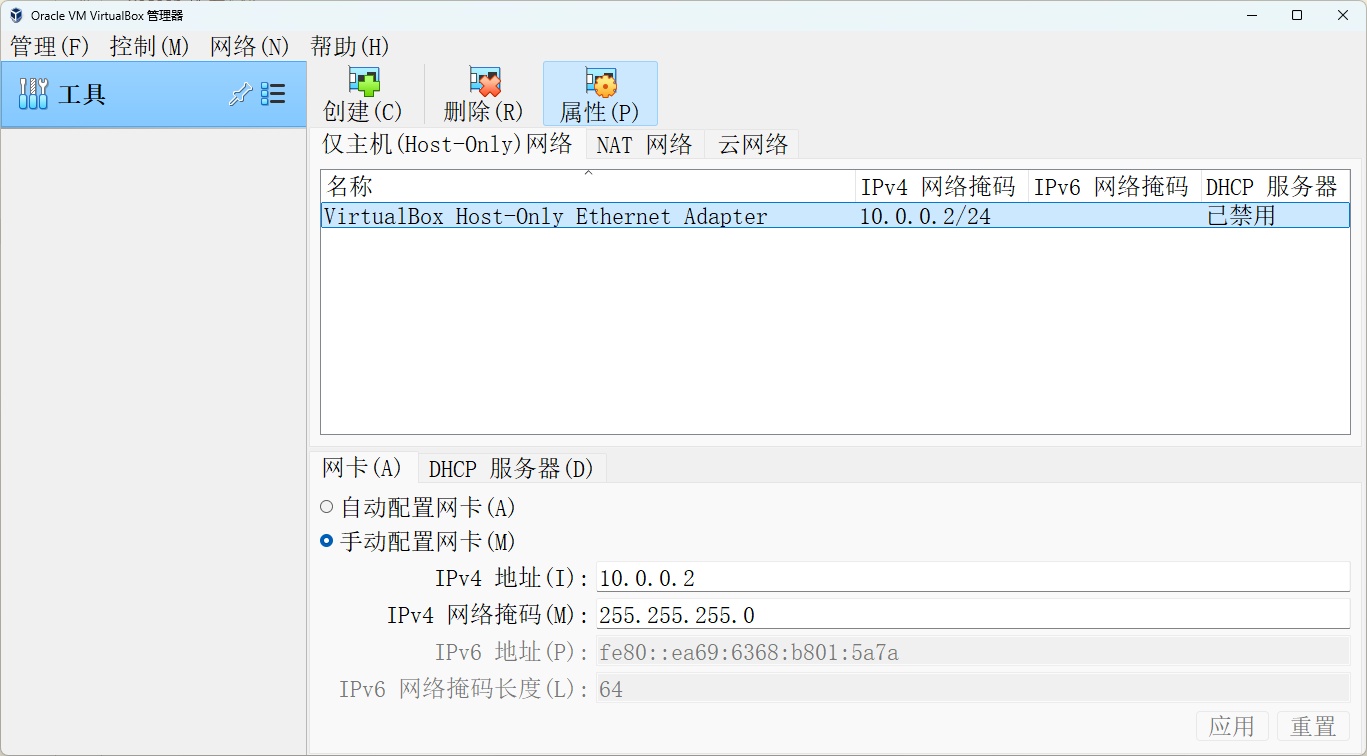
打开 VirtualBox 的网络管理器进行配置。
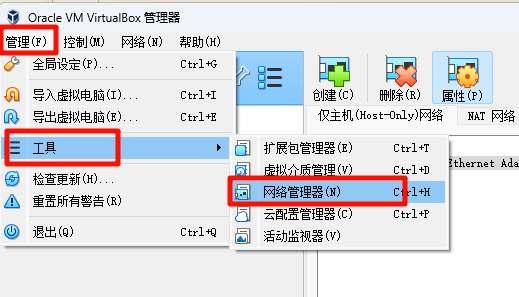
选中
VirtualBox Host-Only Ethernet Adapter,这是虚拟机的仅主机(Host-Only)虚拟网络适配器。修改以下的参数:
IPv4 地址:10.0.0.2
IPv4 网络掩码:255.255.255.0
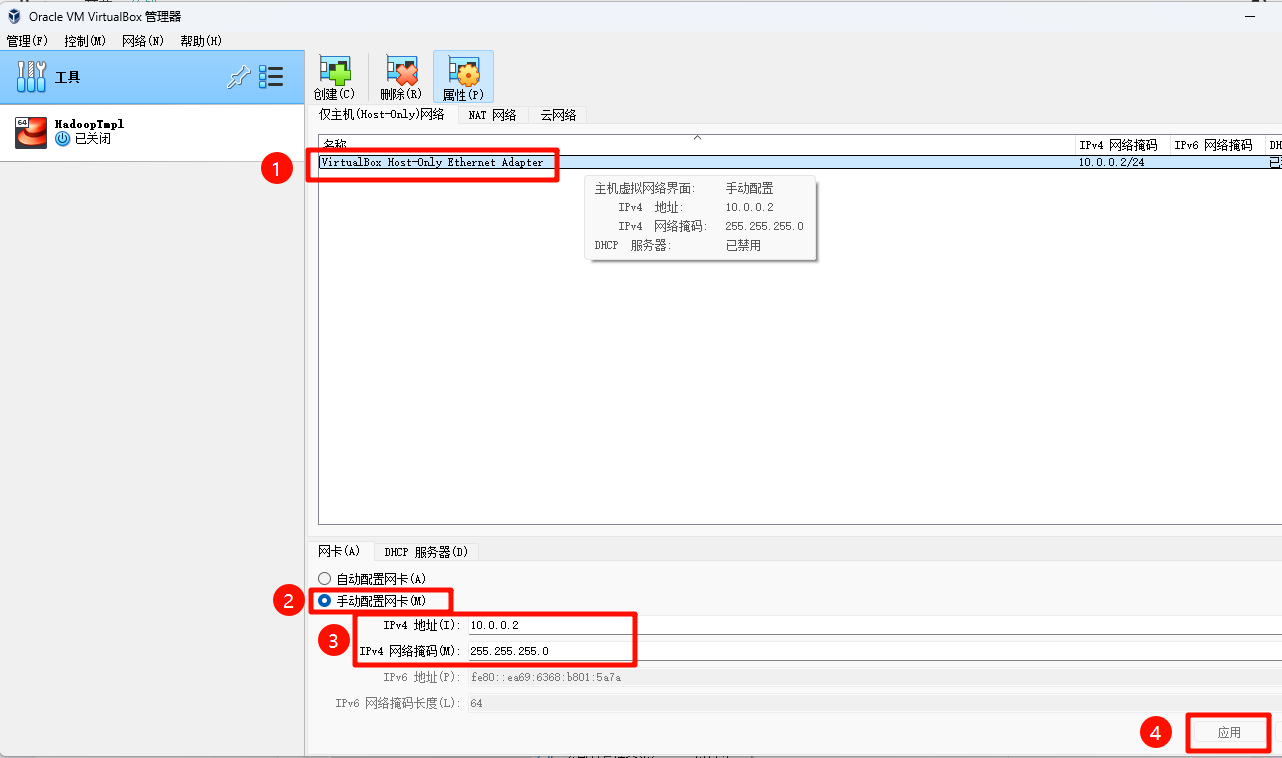
设置
HadoopTmpl虚拟机的网络适配器,指向刚才配置的VirtualBox Host-Only Ethernet Adapter。
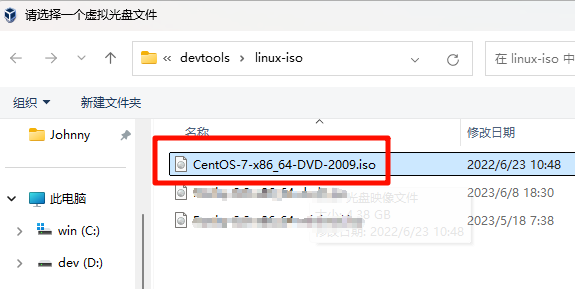
插入安装镜像光盘
CentOS-7-x86_64-DVD-2009.iso,作为本地软件源。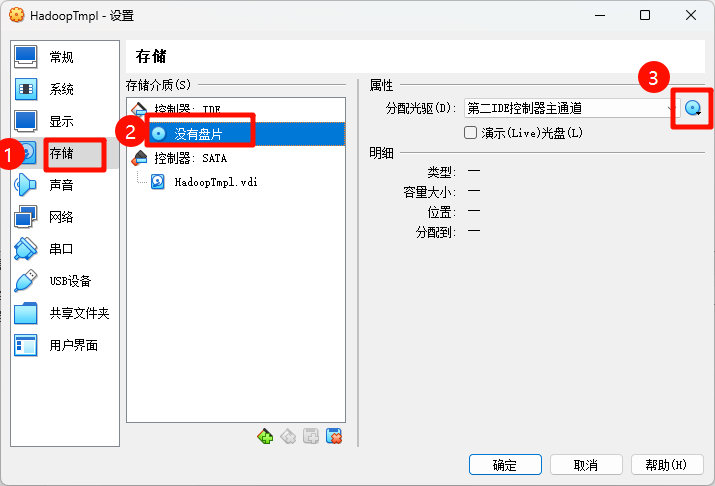
测试模板机
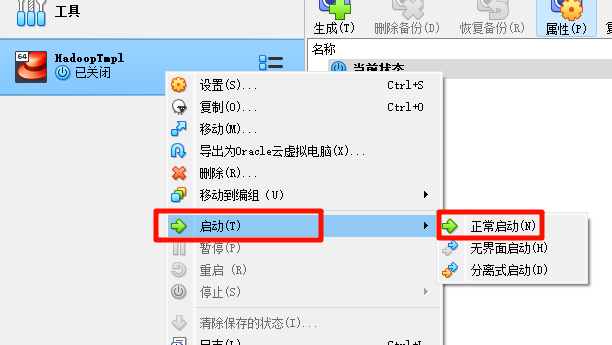
启动模板机,正常启动以后会出现以下界面。
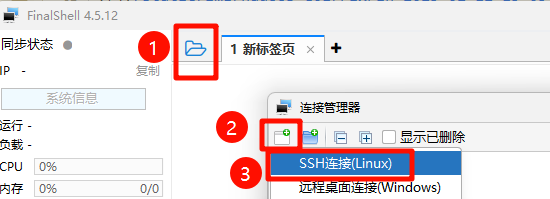
安装 FinalShell,过程略。

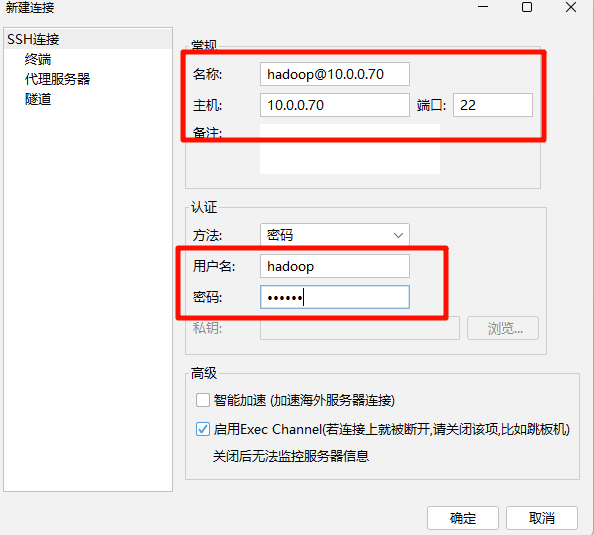
使用 FinalShell 连接模板机,连接配置如下:
连接名称:hadoop@10.0.0.70
主机:10.0.0.70
端口:22
用户名:hadoop
密码:132456
- HadoopTmpl 模板机有2个用户,通常只需要使用 hadoop 用户登录系统即可。
#hadoop用户
用户名:hadoop
密码:132456
#root用户
用户名:root
密码:132456
复制模板机
- 登录模板机以后,修改hosts文件。
sudo vim /etc/hosts
- 在文件后面
新增以下几行。这里主要是为了后面复制出来的虚拟机可以相互通过主机名进行相互访问。
10.0.0.71 nodea替换为你学号后3位
10.0.0.72 nodeb替换为你学号后3位
10.0.0.73 nodec替换为你学号后3位

- 关闭系统防火墙。
systemctl stop firewalld
systemctl disable firewalld
注意:这里为了方便演示部署,选择关闭防火墙,在实际的生成环境中,不能直接关闭防火墙,会有极大的安全隐患。
- 查看系统防火墙状态,确认状态是显示为
Active: inactive (dead)
firewalld.service - firewalld - dynamic firewall daemon
Loaded: loaded (/usr/lib/systemd/system/firewalld.service; disabled; vendor preset: enabled)
Active: inactive (dead)
Docs: man:firewalld(1)
- 关闭 HadoopTmpl 模板机。依次从模板机复制出3台虚拟机,名称,主机名和 IP 地址如下表所示,注意替换为你的学号后3位。
| 虚拟机名称 | 主机名(hostname) | IP地址 |
|---|---|---|
| NodeA | nodea+你学号后3位(例如nodea101) | 10.0.0.71 |
| NodeB | nodeb+你学号后3位(例如nodeb101) | 10.0.0.72 |
| NodeC | nodec+你学号后3位(例如nodec101) | 10.0.0.73 |
- 由于刚复制好的虚拟机都使用同一个IP地址,所以不能同时启动模板机、NodeA、NodeB或NodeC。需要依次启动,登录,并逐一修改为对应的 hostname 和 IP。
- 同时启动 NodeA、NodeB 和 NodeC 3台虚拟机,配置 FinalShell 分别连接3台虚拟机,使用
hadoop用户登录,密码为123456,测试是否能够正常登录。
配置免密登录
免密登录,顾名思义就是不需要输入密码即可登录。免密登录的大致原理,就是在客户端 client 生成一对密钥(包括公钥和私钥),然后将公钥传到服务器。当客户端通过 ssh 登录服务器时,不用再输入密码就能直接登进去,这就是 ssh 免密登录。
Hadoop 的 NameNode 是通过SSH 来启动和停止各个节点上的各种守护进程的,这就需要在节点之间执行指令的时候是不需要输入密码的方式,故我们需要配置 SSH 使用免密登录。
- 保证NodeA、NodeB 和 NodeC 3台虚拟机都处于启动状态。使用 hadoop 用户登录 NodeA 节点。如果使用root登录的可以使用以下命令切换到hadoop用户。
su hadoop
- 使用 ping 命令检查是否能够连通 NodeB 和 NodeC。
ping nodeb+你学号后3位 -c 3
ping nodec+你学号后3位 -c 3
- 正常情况下应该有类似返回信息如下:
64 bytes from nodeb (10.0.0.72): icmp_seq=1 ttl=64 time=0.373 ms
- 如果没有看到以上返回消息,请检查
/etc/hosts是否修改正确,参考 Part1 步骤14。
- 配置免密登录。首先生成密钥对,运行以下命令。直接回车(Enter)3次。
ssh-keygen -t rsa
- 在返回的对话文字中,直接回车(Enter)3次,输出内容类似以下。
Generating public/private rsa key pair.
Enter file in which to save the key (/home/hadoop/.ssh/id_rsa):
Created directory '/home/hadoop/.ssh'.
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /home/hadoop/.ssh/id_rsa.
Your public key has been saved in /home/hadoop/.ssh/id_rsa.pub.
The key fingerprint is:
SHA256:MSUbr5VaCY4KSpsCM0l8uhYWkr5R9iNI05SFuF00jLA hadoop@nodea999
The key's randomart image is:
+---[RSA 2048]----+
|.+=.B+ + . |
|+B.O o.o B o |
|OE% o . = * |
|o%o+ + B |
|+o= o . S |
|.+ |
|. |
| |
| |
+----[SHA256]-----+
- 查看目录下是否有公钥
id_rsa.pub和私钥id_rsa。
cd ~/.ssh
ls
- 可以看到以下2个文件。其中
id_rsa是私钥,id_rsa.pub是公钥。
id_rsa id_rsa.pub
- 执行以下命令,把公钥写入本机授权文件。
cat id_rsa.pub >> authorized_keys
- 查看授权文件内的公钥内容。
cd ~/.ssh
cat authorized_keys
- 可以看到类似以下内容
ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQC1Df9cM8NVGURMj3I86EoiO4Jy6LuuHOc+MC3vnZPJX9ISSXDZ9Qx+a5CCdoZJyySG3IlvAFBLv2Wnv60tDZ9xHEQ0WbkAV/IeDrdRk1OI51/bEGfdPqTLBtic1eXsFC6luc7kbQYuxQRoeovl2UwHNgzAX/xTyUV0uAuvTeggyGWq05I9OiantybrumNUJO8gFO3R9CA/zvNrJbuvVDKT9AAqQpn57jDsHkTiAlGoubKUcgAWy1EbYk7hVCL1gFkMcxDMvSOBoY23oqEFSNrkuho2Cj2fNUinaDNDPPzoqbDwvU9IUCGhgfiNYb4Ub/hoabJRjlcNiEgoD+G79lNd hadoop@nodea你的学号后3位
- 修改 authorized_keys 的权限为444,让
NodeA能够免密登录自身。
chmod 444 authorized_keys
ls -al authorized_keys
- 确认
NodeB和NodeC2个节点都已经启动。在NodaA上面运行以下命令,把公钥拷贝到NodeB和NodeC。
ssh-copy-id -i ~/.ssh/id_rsa.pub nodeb+你学号后3位 -f
ssh-copy-id -i ~/.ssh/id_rsa.pub nodec+你学号后3位 -f
- 系统询问是否连接,输入yes
Are you sure you want to continue connecting (yes/no)? yes
- 输入 hadoop 登录密码
hadoop@nodeb你学号后3位's password:
- 使用以下方法测试免密登录是否配置成功,在NodeA上面分别 SSH 登录
NodeA、NodeB、NodeC。
- 例如:在 NodeA 执行以下命令,使用 SSH 协议登录 NodeB。
ssh hadoop@nodeb+你的学号后3位
- 如果能够成功登录 NodeB 节点,而且不需要输入密码,则表示免密登录成功。输入以下命令退出登录。
exit
修改 Hadoop 配置文件
- 备份和编辑 Hadoop 的 core-site.xml 配置文件。在configuration 标签内添加配置,注意替换为你的学号后3位。
cp /opt/hadoop/etc/hadoop/core-site.xml{,.bak}
vim /opt/hadoop/etc/hadoop/core-site.xml
<configuration>
<!-- HDFS 访问地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://nodea+你学号后3位:8020</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hadoop/tmp</value>
</property>
<property>
<name>fs.trash.interval</name>
<value>1440</value>
</property>
<property>
<name>hadoop.http.staticuser.user</name>
<value>hadoop</value>
</property>
</configuration>
- 备份和编辑 Hadoop 的 hdfs-site.xml 配置文件。请注意替换为你的学号。
cp /opt/hadoop/etc/hadoop/hdfs-site.xml{,.bak}
vim /opt/hadoop/etc/hadoop/hdfs-site.xml
<configuration>
<!-- secondary namenode 访问地址-->
<property>
<name>dfs.secondary.http.address</name>
<value>nodea+你学号后3位:50090</value>
</property>
<!-- HDFS 副本数量 -->
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
</configuration>
- 新建一个 masters 配置文件,写入 Secondary NameNode 的主机名。
vim /opt/hadoop/etc/hadoop/masters
删除原有内容,写入以下内容,注意替换为你的学号后3位。
nodea+你的学号后3位
- 备份和编辑 Hadoop 的 mapred-site.xml 配置文件。注意替换为你的学号后3位。
cp /opt/hadoop/etc/hadoop/mapred-site.xml{,.bak}
vim /opt/hadoop/etc/hadoop/mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>nodea+你学号后3位:10020</value>
<description>Host and port for Job History Server (default 0.0.0.0:10020)</description>
</property>
<property>
<name>mapreduce.application.classpath</name>
<value>$HADOOP_HOME/share/hadoop/mapreduce/*,$HADOOP_HOME/share/hadoop/mapreduce/lib/*,$HADOOP_HOME/share/hadoop/common/*,$HADOOP_HOME/share/hadoop/common/lib/*,$HADOOP_HOME/share/hadoop/yarn/*,$HADOOP_HOME/share/hadoop/yarn/lib/*,$HADOOP_HOME/share/hadoop/hdfs/*,$HADOOP_HOME/share/hadoop/hdfs/lib/*</value>
</property>
</configuration>
- 备份和编辑 Hadoop 的 yarn-site.xml 配置文件。注意替换为你的学号后3位。
cp /opt/hadoop/etc/hadoop/yarn-site.xml{,.bak}
vim /opt/hadoop/etc/hadoop/yarn-site.xml
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>nodea+你学号后3位</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
- 编辑 workers ,清除原来的所有内容,增加配置 DataNode 节点信息。注意替换为你的学号后3位。
vim /opt/hadoop/etc/hadoop/workers
- 删除原有内容,写入以下内容。
nodeb+你学号后3位
nodec+你学号后3位
从Hadoop 3.0 开始,slaves 已经启用,改用 workers 来进行替代配置数据节点信息。
- 修改 hadoop-env.sh,在第1行加入以下代码。
vim /opt/hadoop/etc/hadoop/hadoop-env.sh
export JAVA_HOME=/opt/jdk8
- 把
NodeA节点的 Hadoop /opt/hadoop/etc/hadoop 下所有配置文件发送到NodeB和NodeC。如果上面的配置文件有修改,也需要同步发送到NodeB和NodeC节点。
cd /opt/hadoop/etc/
scp -r hadoop hadoop@nodeb+你学号后3位:/opt/hadoop/etc/
scp -r hadoop hadoop@nodec+你学号后3位:/opt/hadoop/etc/
- 格式化 HDFS。
hdfs namenode -format
- 在输出的内容中,如果能看到以下这句信息,说明格式化成功。
2022-01-24 14:32:54,209 INFO common.Storage: Storage directory /opt/hadoop/tmp/dfs/name has been successfully formatted.
- 创建 Hadoop 启动脚本,注意替换为你的学号后3位。
vim /opt/hadoop/sbin/start-hdp.sh
#!/usr/bin/env bash
echo "Start Hadoop by 你的学号后3位"
start-dfs.sh
start-yarn.sh
mapred --daemon start historyserver
- 创建 Hadoop 停止脚本,注意替换为你的学号后3位。
vim /opt/hadoop/sbin/stop-hdp.sh
#!/usr/bin/env bash
echo "Stop Hadoop by 你的学号后3位"
mapred --daemon stop historyserver
stop-yarn.sh
stop-dfs.sh
- 创建 Hadoop 重启脚本,注意替换为你的学号后3位。
vim /opt/hadoop/sbin/restart-hdp.sh
#!/usr/bin/env bash
stop-hdp.sh
start-hdp.sh
- 修改创建的脚本的权限。
cd /opt/hadoop/sbin/
chmod 744 start-hdp.sh stop-hdp.sh restart-hdp.sh
- 使用脚本启动 Hadoop。
start-hdp.sh
验证免密登录
- 在
NodeB和NodeC2个节点分别执行以下命令,查看是否包含来自NodeA的公钥。
cd ~/.ssh
cat authorized_keys
验证时间是否同步
- 在
NodeB和NodeC2个节点分别执行以下命令,查看时间是否与NodeA同步。
date
如果时间不同步,可以执行以下语句,尝试强制同步时间。
chronyc -a makestep
验证 Hadoop 是否正常启动
- 在
NodeA输入jps命令,观察是否有以下进程。
jps
- 正常应该有类似以下信息返回:
NameNode
Jps
ResourceManager
SecondaryNameNode
JobHistoryServer
- 在
NodeA输入以下命令查看机架拓扑是否有NodeB和NodeC的信息
hdfs dfsadmin -printTopology
- 正常应该有类似以下信息返回:
Rack: /default-rack
10.0.0.72:9866 (nodeb你的学号后3位)
10.0.0.73:9866 (nodec你的学号后3位)
- 在
NodeB和NodeC分别输入jps命令,观察是否有以下进程。
jps
- 正常应该有类似以下信息返回:
DataNode
NodeManager
Jps
验证 HDFS 是否正常工作
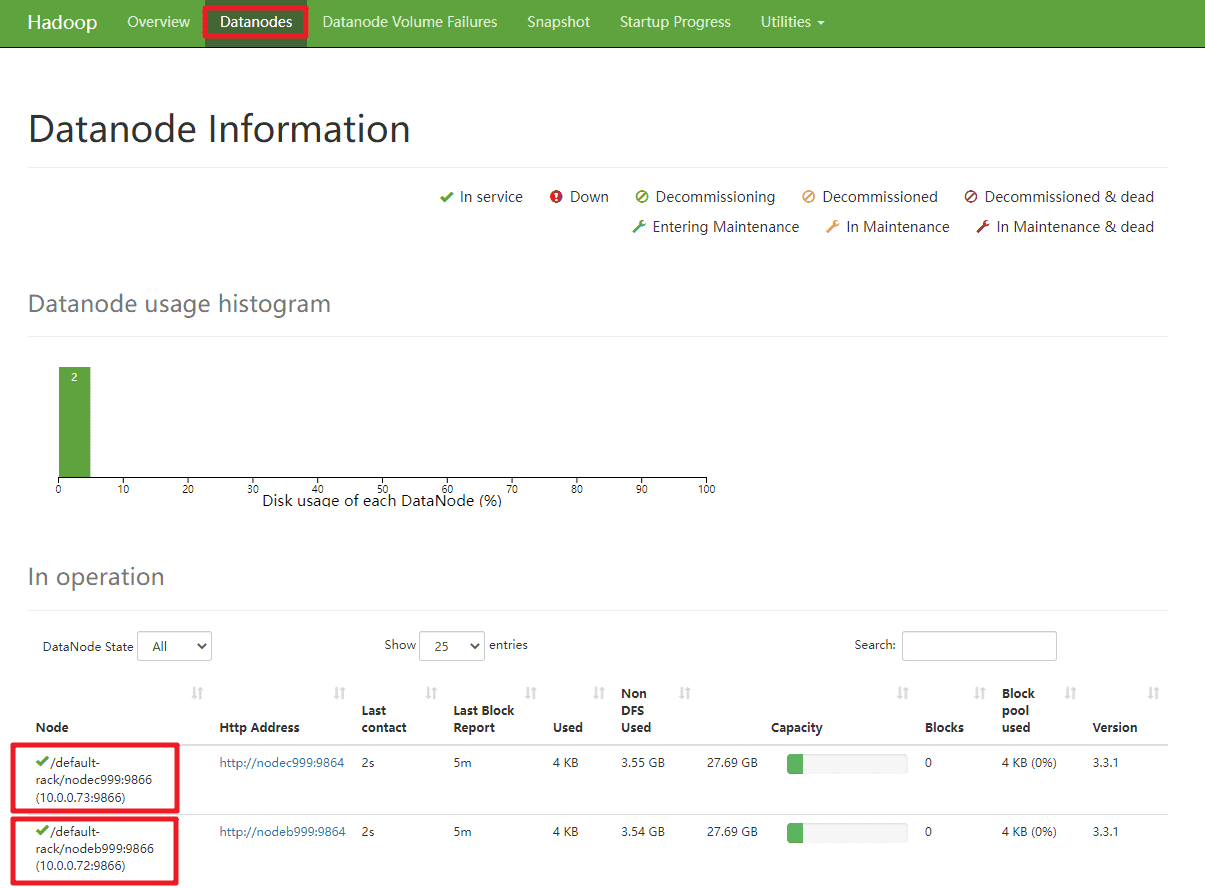
打开宿主机浏览器,访问 HDFS Web 界面 http://10.0.0.71:9870/
查看 NameNode 是否 Active
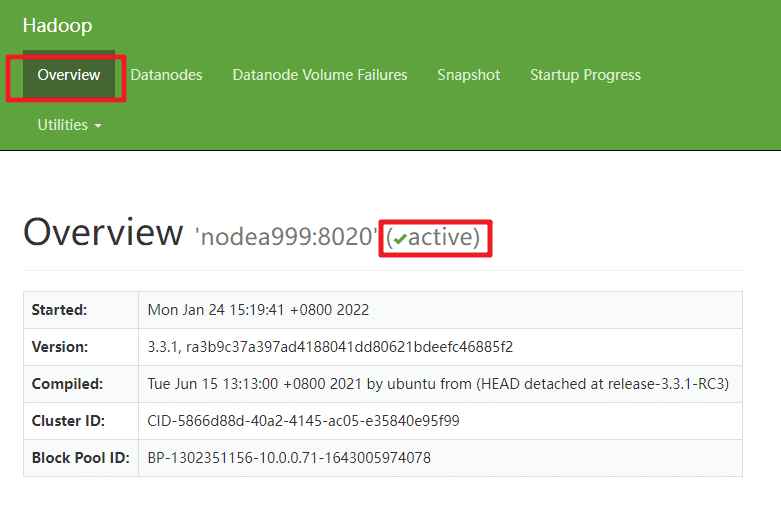
查看2个节点 DataNode 服务状态是否正常。
上传
countryroad.txt到NodeA的/home/hadoop把
countryroad.txt从 CentOS 文件系统上传到 HDFS 文件系统。
hdfs dfs -mkdir /part2
hdfs dfs -put /home/hadoop/countryroad.txt /part2
hdfs dfs -ls /part2
验证 MapReduce 是否正常工作
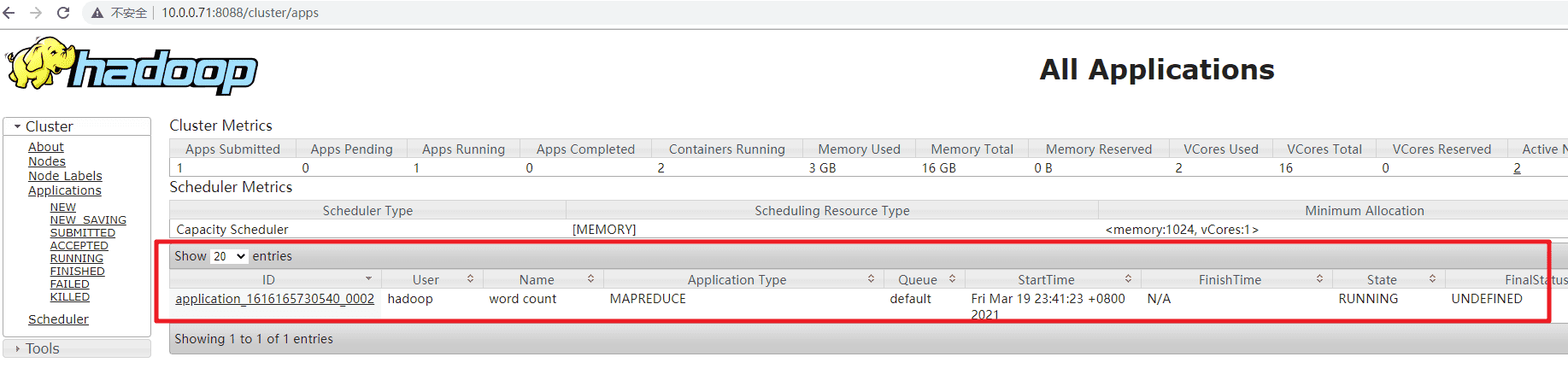
- 运行 Hadoop 自带的 Wordcount 程序,观察输出的内容。
cd $HADOOP_HOME/share/hadoop/mapreduce
hadoop jar hadoop-mapreduce-examples-3.3.1.jar wordcount /part2/countryroad.txt /output
- 如果输出的日志内容包含类似以下信息,则表示执行成功
2022-01-24 15:48:51,712 INFO mapreduce.Job: Job job_xxxxxxx completed successfully
- 程序执行过程中,可以访问 Yarn Web 界面查看任务进展。http://10.0.0.71:8088/cluster/apps
- 等待程序运行完毕,观察输出的内容
hdfs dfs -cat /output/part-r-00000
任务1.2 搭建 Hadoop 开发环境
【任务目的】
- 掌握 JDK 的安装和环境变量的设置
- 掌握 IDEA 的安装和使用
- 掌握 Maven 的安装、配置和使用命令
【任务环境】
- Windows 7 以上64位操作系统
【任务资源】
- JDK 8 - Java Development Kit是 Oracle 公司针对Java开发人员发布的免费软件开发工具包,是 Java 开发必备的开发工具。
- Intellij IDEA - 业界简称IDEA,是 jetbrains 公司推出的和 Eclipse 齐名的 Java 集成开发环境(IDE)。
- Apache Maven - Apache Maven,是一个软件项目管理及自动构建工具,由Apache软件基金会所提供。是 Java 构建打包最广泛使用的工具。
【任务说明】
- 为了能够使用编程的方式访问和调用 Hadoop 平台的功能,我们必须部署一套基于 Java 的编程环境。本次任务主要是完成 JDK、Maven 和 IDEA的安装和配置。
【任务内容】
- 完成 JDK、IDEA 和 Maven 的安装与配置
- 编写测试用例测试之前的软件安装是否成功
【任务步骤】
安装 JDK 8
- 在 Windows 运行安装 jdk-8u261-windows-x64.exe,安装过程略。此处以安装到
d:\jdk8为例。安装完结束以后目录架构如下:目录架构如下:
d:\jdk8
|-bin/
|-lib/
|-include/
|-jre/
|-legal/
|-javafx-src.zip
|-jmc.txt
|-src.zip
|-COPYRIGHT
|-release
|-LICENSE
|-README.html
- 进入Windows的环境变量配置界面,配置以下环境变量。如果系统C盘会还原,每次重启电脑都需要配置此环境变量。注意修改 JDK 的安装目录为你实际安装目录。

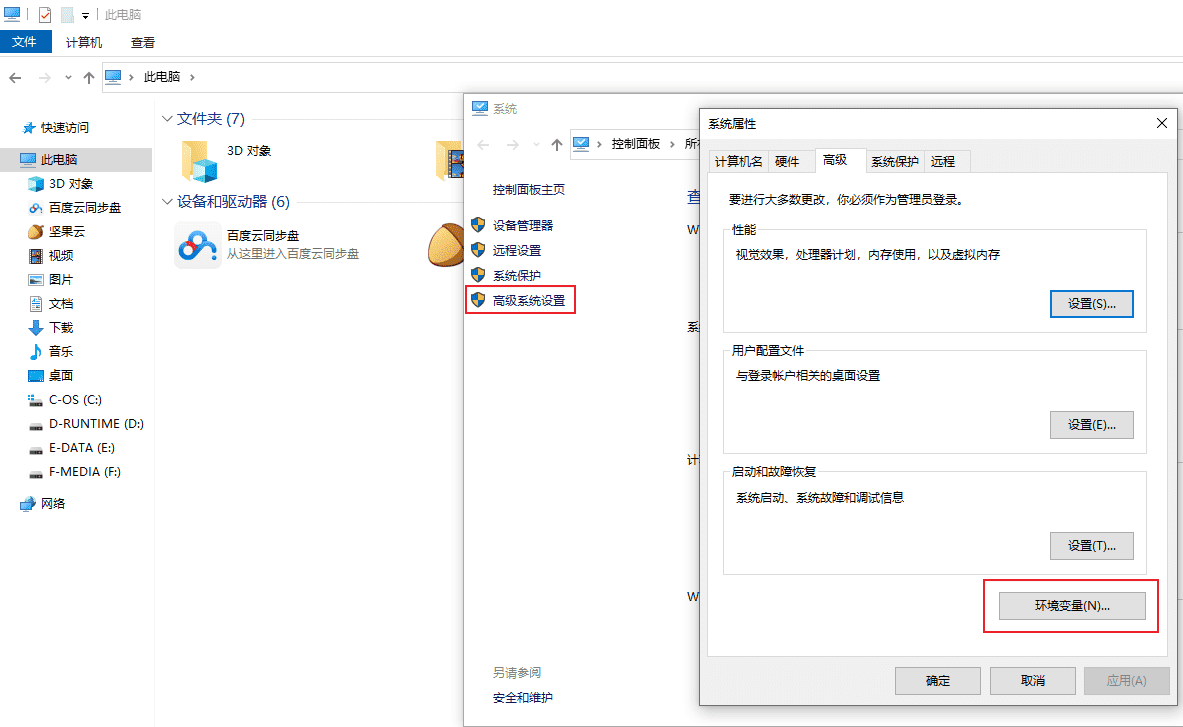
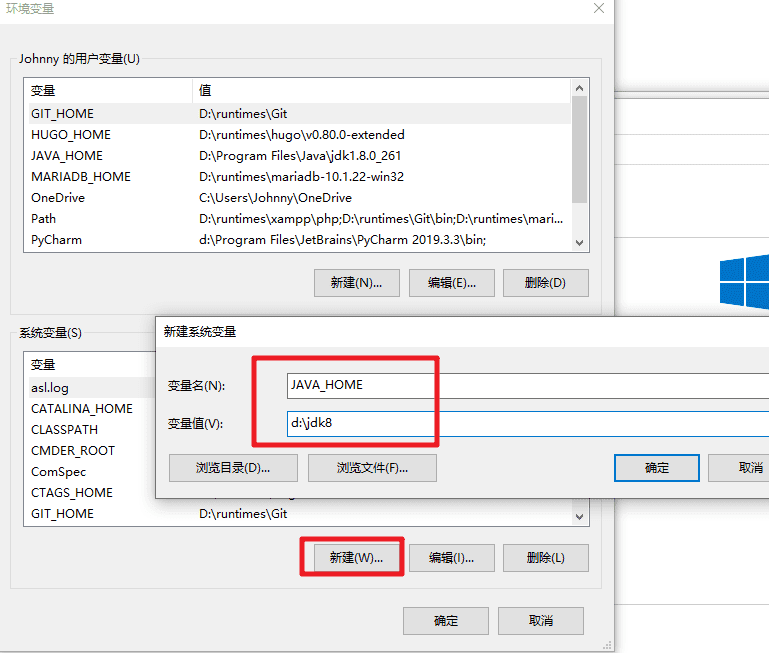

#新增
JAVA_HOME=D:\jdk8
CLASSPATH=%JAVA_HOME%\lib\dt.jar;%JAVA_HOME%\lib\tools.jar
#修改PATH,在PATH环境变量原有值后面追加
;%JAVA_HOME%\bin;
- 打开Windows 的命令行终端,运行以下命令,测试是否有
JDK的版本输出。
java -version
- 正常情况会有类似以下内容输出
java version "1.8.0_271"
Java(TM) SE Runtime Environment (build 1.8.0_271-b09)
Java HotSpot(TM) 64-Bit Server VM (build 25.271-b09, mixed mode)
安装 IDEA
- 运行
ideaIC-2021.2.1.exe,指定目录安装 IDEA,这里以d:\idea为例。安装完成以后目录架构如下:
d:\idea\ideaIC-2021.2.1.win
|-bin\
|-build.txt
|-jbr\
|-lib\
|-license
|-LICENSE.txt
|-NOTICE.txt
|-plugins\
|-product-info.json
|-redist\
- 编辑
d:\idea\ideaIC-2021.2.1.win\bin目录下的idea.exe.vmoptions和idea64.exe.vmoptions,在文件末尾加上以下代码,让 IDEA 默认使用UTF8编码。
-Dfile.encoding=UTF-8
安装和配置 Maven 3
- 解压
apache-maven-3.6.3-bin.zip,这里以解压到d:\maven363为例。在Maven 安装目录下创建一个repos目录,解压repos.zip到repos目录下,里面包含 hadoop 开发包的仓库(Repository)。
d:\maven363
|-bin/
|-boot/
|-conf/
|-lib/
|-LICENSE
|-NOTICE
|-README.txt
|-repos/
- 编辑
d:\maven363\conf\settings.xml文件。在<settings>标签内新增本地仓库路径设置。<localRepository>标签内内容注意修改为你的 Maven 的实际安装路径。
<localRepository>D:/maven363/repos</localRepository>
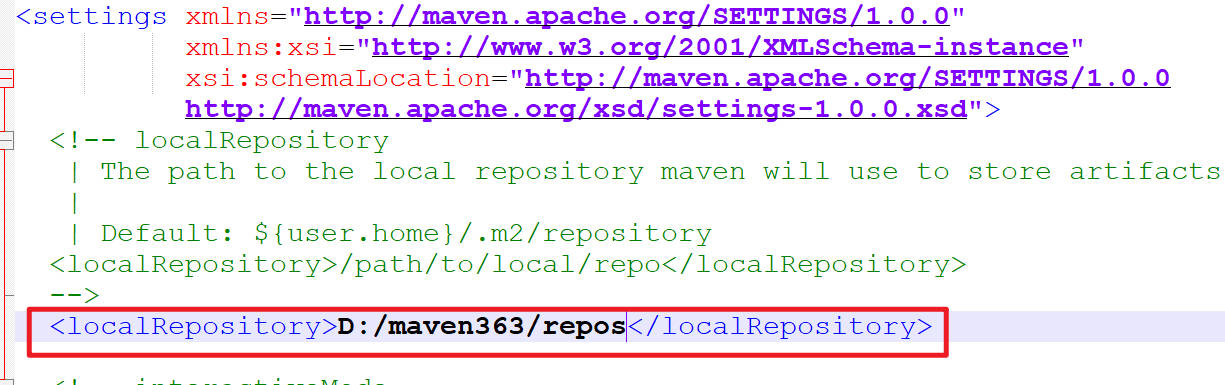
注意:这个XML的标签,需要放在 XML 的注释 外,放在注释内的内容是无法生效的。
- 编辑
d:\maven363\conf\settings.xml文件。在约148行<mirrors>标签内增加远程仓库镜像地址。开发过程中依赖的 Jar 包可以通过配置从此地址下载。
- 如果电脑可以联网,可以修改指向阿里云的仓库镜像。
<mirror>
<id>nexus-aliyun</id>
<mirrorOf>*</mirrorOf>
<name>Nexus aliyun</name>
<url>http://maven.aliyun.com/nexus/content/groups/public</url>
</mirror>
注意:这个XML的标签,需要放在 XML 的注释 外,放在注释内的内容是无法生效的。
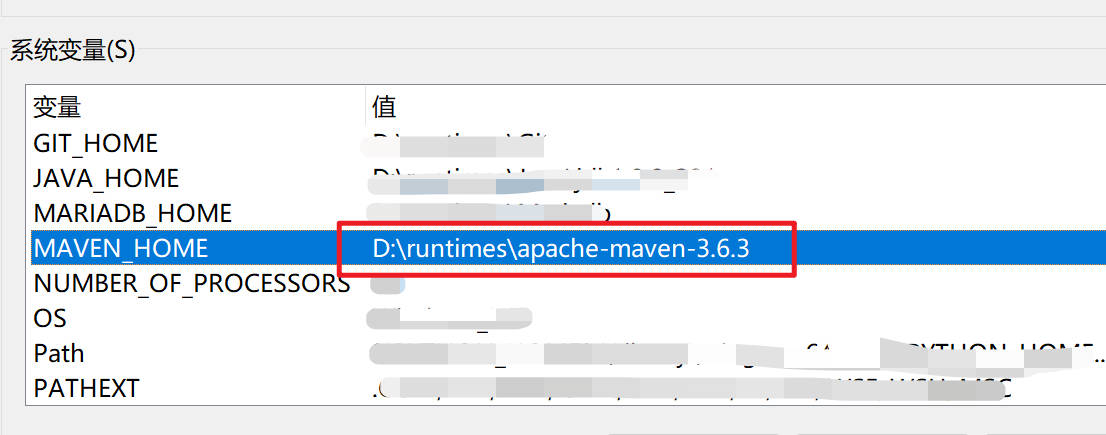
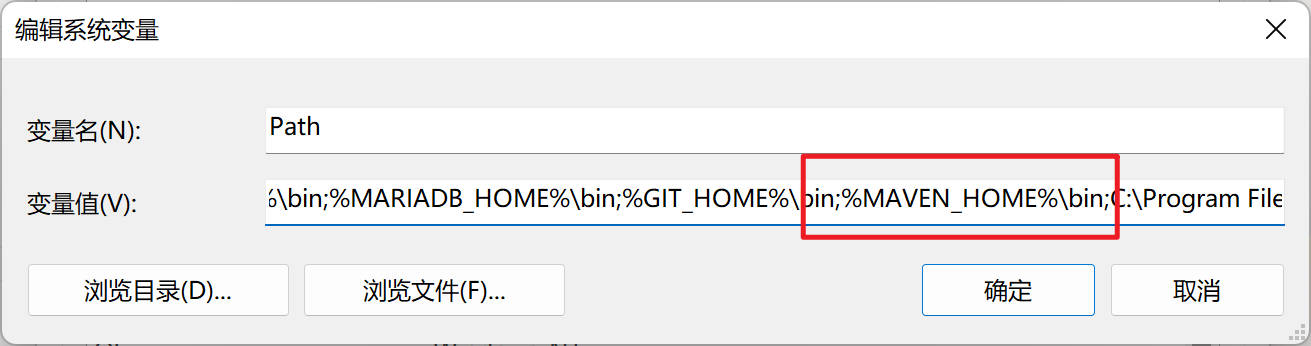
- 进入Windows的环境变量配置界面,配置以下环境变量。可参考步骤2
#新增
MAVEN_HOME=D:\maven363
#修改PATH,在PATH环境变量原有值后面追加
;%MAVEN_HOME%\bin;
- 以下截图仅供参考,请根据你自己的 Maven 路径设置。
- 打开Windows 的命令行终端,运行以下命令,测试是否能够输出你的 mvn 脚本所在路径。
where mvn
- 正常会输出你的 mvn 路径,以下截图仅供参考。

- 打开Windows 的命令行终端,运行以下命令,测试是否有
Maven的版本输出。
mvn -version
安装和配置 IDEA
启动IDEA,运行
d:\idea\ideaIC-2021.2.1.win\bin\idea.exe。新建一个项目。
新建一个 Maven 项目,
Project SDK选择 1.8,如果没有,则点击Add JDK...,指向你的 JDK 的安装目录。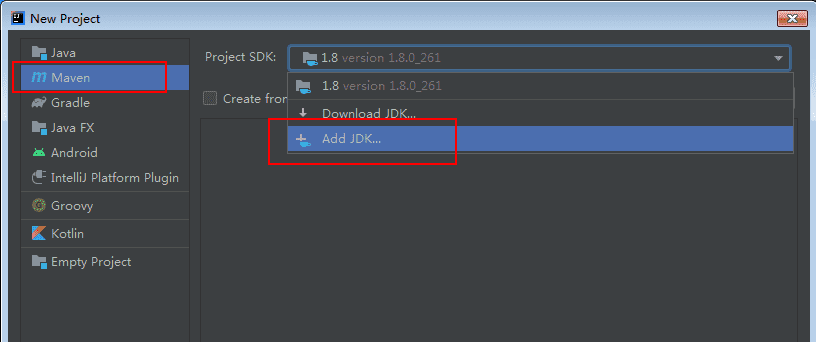
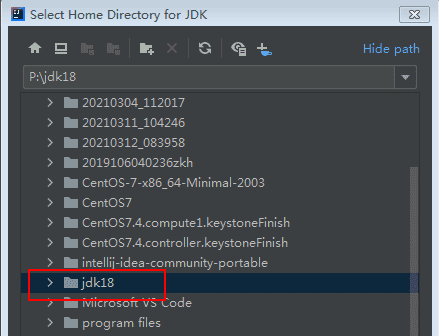
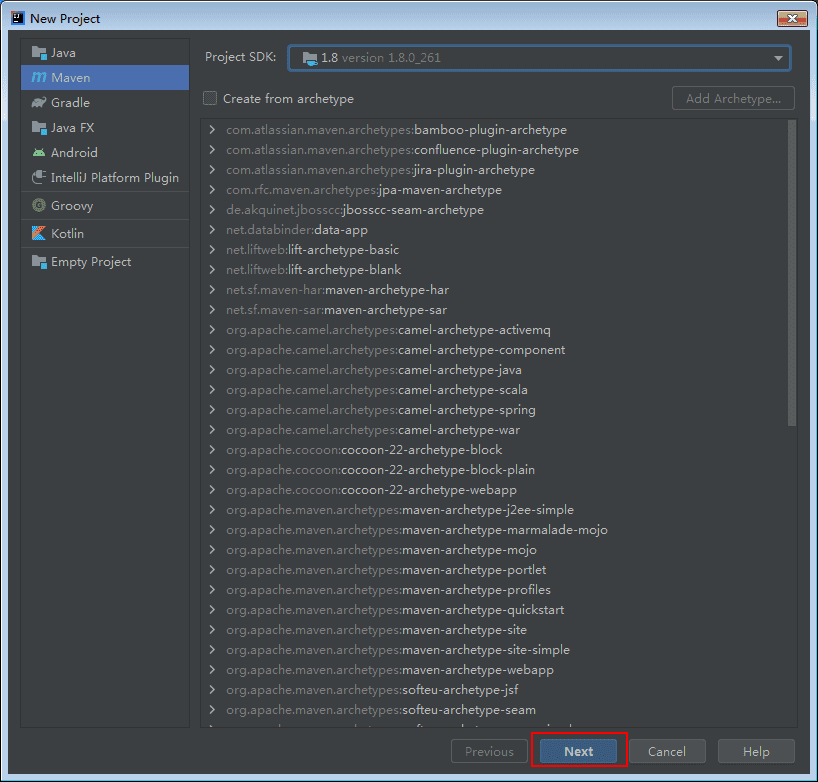
新建一个开发项目,命名为
hadoopexp+你学号后3位。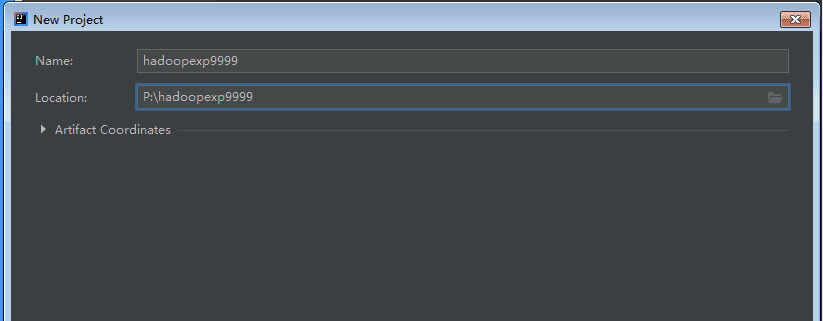
创建成功以后,可以看到项目的整体目录架构。
修改 IDEA 的 Maven 配置,指向本地安装的 Maven。这里注意替换为你的 Maven 的实际安装目录。

修改项目下的
pom.xml文件,此文件是 Maven 项目的配置文件。
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>hadoop</groupId>
<artifactId>hadoop-exp</artifactId>
<version>1.0</version>
<packaging>jar</packaging>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<maven.compiler.encoding>UTF-8</maven.compiler.encoding>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
<hadoop.version>3.3.1</hadoop.version>
</properties>
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.13</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-client</artifactId>
<version>1.3.1</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-server</artifactId>
<version>1.3.1</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-server</artifactId>
<version>1.3.1</version>
</dependency>
<dependency>
<groupId>org.mockito</groupId>
<artifactId>mockito-core</artifactId>
<version>3.9.0</version>
<scope>test</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-jar-plugin</artifactId>
<version>3.2.0</version>
<configuration>
<archive>
<!--<manifestFile>${project.build.outputDirectory}/META-INF/MANIFEST.MF</manifestFile>-->
<manifest>
<!-- main()所在的类,注意修改为你的Main主类 -->
<mainClass>hadoop.mapreduce.wc.WordCountMain</mainClass>
</manifest>
</archive>
</configuration>
</plugin>
</plugins>
</build>
</project>
在项目
hadoop-exp\src\main\java下创建一个名为hadoop+你学号后3位的包。注意替换为你学号后3位。
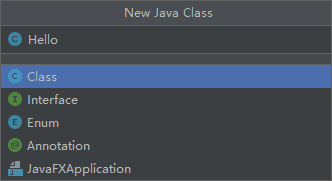
在你创建的包下面,再创建一个名为
Hello的类(class)。
在
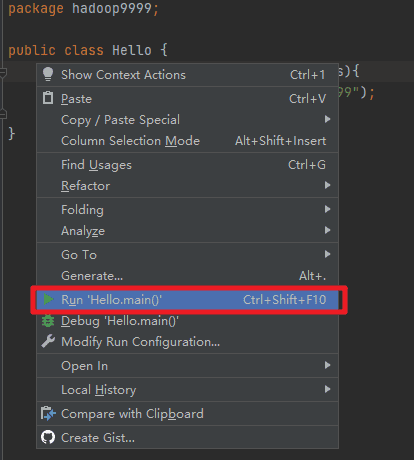
Hello这个类中,编写一个main方法,打印出以下内容。记录你编写的代码,注意替换为你学号后3位。
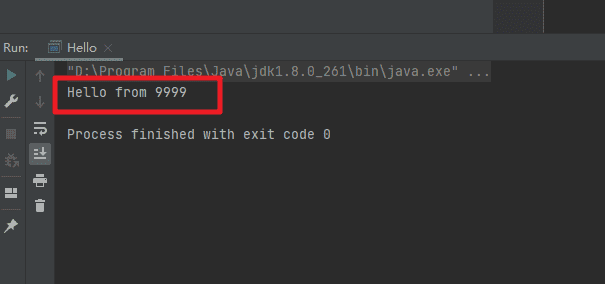
Hello from 你学号后3位
JUnit 是 Java 开发中最常用的单元测试框架,可以帮助测试我们编写的代码。JUnit 非常容易上手。我们可以新建一个 JUnit 测试类学习使用它。
在项目
hadoop-exp\src\test\java下创建一个名为hadoop+你学号后3位的包。注意替换为你学号后3位。在你刚创建的包下面创建一个名为
HelloJUnit的类。编辑
HelloJUnit类,输入下面的代码,运行查看测试结果。注意替换为你学号后3位。
package hadoop+你学号后3位;
import org.junit.Test;
import static org.junit.Assert.*;
public class HelloJUnit {
@Test
public void test1(){
//assertEquals第1个参数时期待值,第2个参数是我们需要测试的值
assertEquals(2,1+1);
assertNotEquals("帅哥","帅锅");
assertFalse(3==(1+1));//断定参数是 False
assertTrue(2==(1+1));//断定参数是 True
//字符串的 split 方法是根据第一个参数字符来把字符串分切为一个字符串数组
String[] strArr="唱,跳,RAP,篮球".split(",");
assertEquals("唱",strArr[0]);
assertEquals("跳",strArr[1]);
assertEquals("RAP",strArr[2]);
assertEquals("篮球",strArr[3]);
}
}
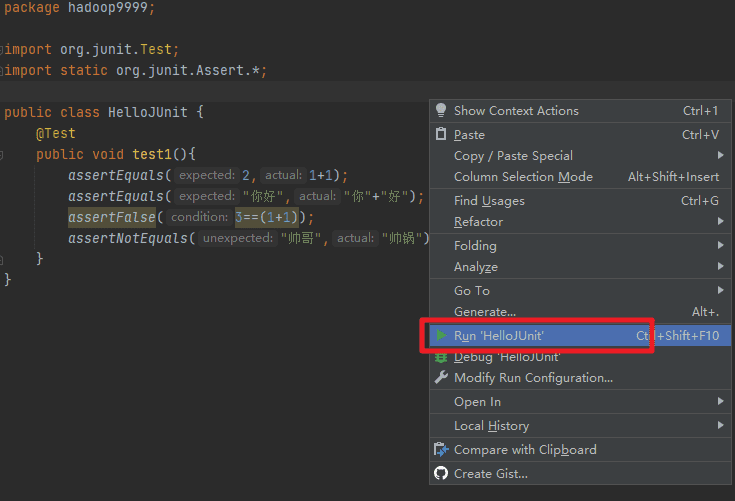
如果结果显示是绿色的勾,则表示单元测试成功。如果是交叉,则表示测试失败。
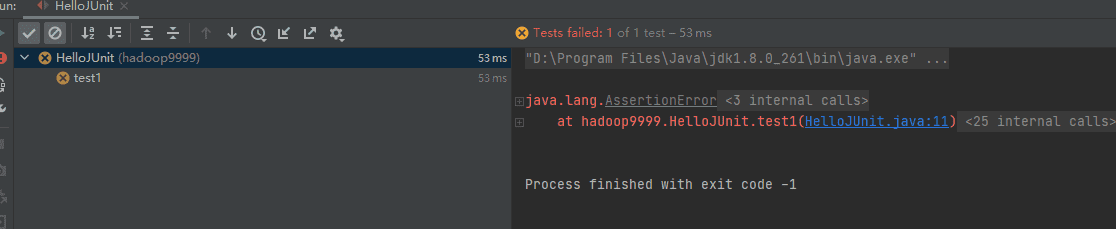
修改以上
HelloJUnit类,重新运行,让测试成功。并记录你修改的代码。编写一个
test2方法,测试以下2个字符串是否相等。
字符串1:1ll1ll1l11ll1l
字符串2:1ll1ll1ll1ll1l
【常见问题】
1. NodeA节点NameNode或SecondaryNameNode 无法启动。并且日志提示“/opt/hadoop/tmp/dfs/namesecondary is in an inconsistent state”。
答:可能是因为多次格式化或者配置文件没有同步导致的错误。
- (1) 首先把
NodeA节点的 Hadoop /opt/hadoop/etc/hadoop 下所有配置文件发送到NodeB和NodeC。
cd /opt/hadoop/etc/
scp -r hadoop hadoop@nodeb+你学号后3位:/opt/hadoop/etc/
scp -r hadoop hadoop@nodec+你学号后3位:/opt/hadoop/etc/
- (2) 删除/opt/hadoop/tmp 下的所有内容。
- (3) 再次执行 HDFS 格式化。
hdfs namenode -format
2. Hadoop 执行 MapReduce 任务失败,并且日志伴有“Note: System times on machines may be out of sync. Check system time and time zones.”
答:可能是由于虚拟机节点之间的时间不同步导致的。
- (1) 在
NodeB和NodeC执行以下语句,尝试强制与NodeA同步时间。
chronyc -a makestep
- (2) 重启 Hadoop。
3. YARN 的 ResourceManager 进程找不到,而且日志报java.lang.NullPointerException
java.lang.NullPointerException
at org.apache.hadoop.yarn.server.api.protocolrecords.impl.pb.NodesToAttributesMappingRequestPBImpl.initNodeAttributesMapping(NodesToAttributesMappingRequestPBImpl.java:102)
at org.apache.hadoop.yarn.server.api.protocolrecords.impl.pb.NodesToAttributesMappingRequestPBImpl.getNodesToAttributes(NodesToAttributesMappingRequestPBImpl.java:117)
at org.apache.hadoop.yarn.nodelabels.store.op.FSNodeStoreLogOp.getNodeToAttributesMap(FSNodeStoreLogOp.java:46)
at org.apache.hadoop.yarn.nodelabels.store.op.NodeAttributeMirrorOp.recover(NodeAttributeMirrorOp.java:57)
at org.apache.hadoop.yarn.nodelabels.store.op.NodeAttributeMirrorOp.recover(NodeAttributeMirrorOp.java:35)
at org.apache.hadoop.yarn.nodelabels.store.AbstractFSNodeStore.loadFromMirror(AbstractFSNodeStore.java:121)
at org.apache.hadoop.yarn.nodelabels.store.AbstractFSNodeStore.recoverFromStore(AbstractFSNodeStore.java:150)
at org.apache.hadoop.yarn.server.resourcemanager.nodelabels.FileSystemNodeAttributeStore.recover(FileSystemNodeAttributeStore.java:95)
答:在/tmp目录下找到以下 yarn 相关的目录进行删除
/tmp/hadoop-yarn-hadoop
/tmp/hadoop-yarn-root
4. HDFS Web 界面上传文件到 HDFS 失败,提示Couldn't upload the file。

答:这是由于上传的过程中,调用了 DataNode 的接口,而这个接口使用了主机名,如果 Windows 无法识别主机名,则无法找到对应 IP 地址进行上传。只需要配置 Hadoop 的 NameNode 和 DataNode 的 Hosts 即可。
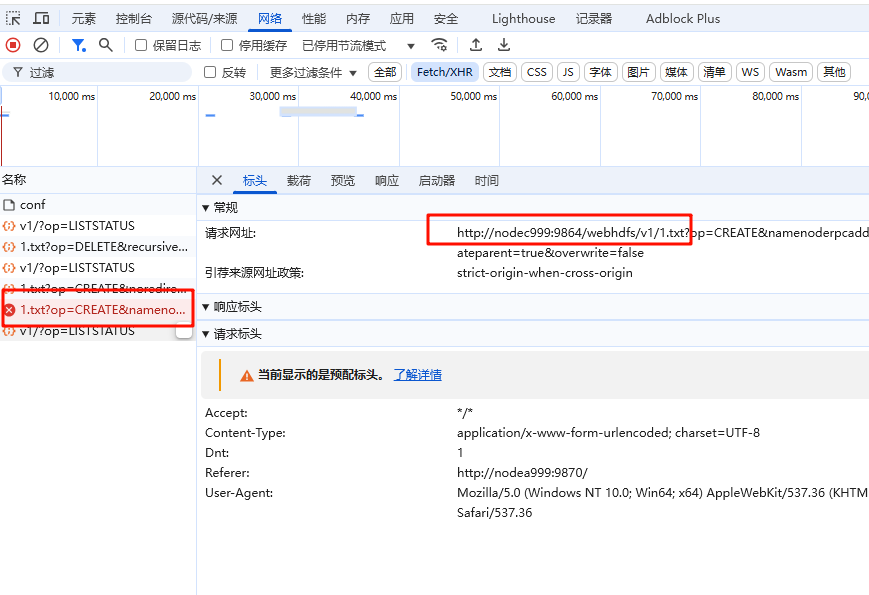
(1) 使用文本编辑器打开 Windows 的
C:\Windows\System32\drivers\etc\hosts文件。(2)在文件末尾加入以下配置,注意替换学号,并保存。
10.0.0.71 nodea+你的学号后三位
10.0.0.72 nodeb+你的学号后三位
10.0.0.73 nodec+你的学号后三位
- (3)使用http://nodea999:9870/ 访问 HDFS Web 界面。
