【版本】
当前版本号v20200418
| 版本 | 修改说明 |
|---|---|
| v20200418 | 修改 hosts 的说明,增加常见问题解答 |
| v20200408 | 加入hosts的检查 |
| v20200407 | 修正实验5.3一处描述错误 |
| v20200406 | 修复实验5.3复制命令为cp |
| v20200322 | 初始化版本 |
【实验名称】 实验5.1:RDD DataFrame API 练习
【实验目的】
掌握RDD DataFrame 的相关 API
【实验原理】
DataFrame 是一种以 RDD 为基础的分布式数据集,类似于传统数据库中的二维 表 格。 DataFrame 与 RDD 的 主 要区 别在 于, 前 者带 有 schema 元信 息 ,即 DataFrame 所表示的二维表数据集的每一列都带有名称和类型。采用RDD的toDF()算子将RDD转为DataFrame。
rdd 转换 DataFrame API:
rdd.toDF(schema=None, sampleRatio=None)
- Schema:指表的结构信息
- samplingRatio:指定用于类型推断的样本的比例。
SparkSession 创建 DataFrame
SparkSession.createDataFrame(data, schema=None, samplingRatio=None, verifySchema=True)
- schema :指定表结构。
- samplingRatio:指定用于类型推断的样本的比例。 含义是:如果df的某列的类型不确定,则抽样百分之samplingRatio的数据来看是什么类型。
- verifySchema:验证每行的数据类型是否符合schema的定义。
【实验环境】
- 操作系统:Ubuntu 16.04
- Spark:Spark 2.x
【实验要求】
- 请补充以下代码,按照要求输入结果。注意替换你的学号和姓名。
rdd1=sc.parallelize([('Michael','329'),('Andy','330'),('你的姓名','你的学号后三位')])
<补充代码>
期望输出:
+--------+------+
|stuname |stuid |
+--------+------+
|Michael | 329 |
| Andy | 330 |
|你的姓名| 你的学号后三位|
+--------+------+
- 使用 createDataFrame 函数创建以下内容并输出。注意替换你的学号和姓名
from pyspark.sql import Row
<补充代码>
期望输出:
[Row(stuname='Michael', stuid='329'),
Row(stuname='Andy', stuid='330'),
Row(stuname='你的姓名', stuid='你的学号后三位')]
- 请补充以下代码,按照要求输入结果。
from pyspark.sql.types import *
rdd1=sc.parallelize([('Michael',29,73.5)])
schema = StructType(<补充代码>)
df = rdd1.toDF(schema)
df.printSchema()
期望输出:
root
|-- name: string (nullable = false)
|-- age: integer (nullable = true)
|-- weight: float (nullable = true)
- 请补充以下代码,按照要求输入结果。
rdd = sc.parallelize( [{'name': 'Alice', 'age': 25}])
spark.createDataFrame(rdd, "<补充代码>").printSchema()
期望输出:
root
|-- name: string (nullable = true)
|-- age: integer (nullable = true)
- 请补充以下代码,按照要求输入结果。
rdd = sc.parallelize( [('Michael','329')])
spark.createDataFrame(rdd, "name: string, age: int").<补充代码>
[('name', 'string'), ('age', 'int')]
【实验名称】 实验5.2:自行设计实现RDD转为DataFrame
【实验目的】
掌握RDD转为DataFrame的方法
【实验原理】
同上
【实验环境】
- 操作系统:Ubuntu 16.04
- Spark:Spark2.x
【实验资源】
数据下载:
https://pan.baidu.com/s/1kXZ-bMTMXA1A3rszHebMBA#提取码t7q1
【实验背景】
emp.csv是职工表。相关字段名如下图所示:
| 序号 | 名称 | 类型 | Nullable |
|---|---|---|---|
| 1 | EMPNO | integer | true |
| 2 | ENAME | string | true |
| 3 | JOB | string | true |
| 4 | MGR | string | true |
| 5 | HIREDATE | string | true |
| 6 | SAL | integer | true |
| 7 | COMM | integer(空白转为0) | true |
| 8 | DEPTNO | integer | true |
dept.csv是部门表。相关字段名如下图所示:
| 序号 | 名称 | 类型 | Nullable |
|---|---|---|---|
| 1 | DEPTNO | integer | true |
| 2 | DNAME | string | true |
| 3 | LOC | string | true |
【实验要求】
请按要求完成以下实验内容,要求在实验报告记录你的思路,代码和结果。
修改 emp.csv 的第一行数据 SMITH 为你的姓名。上传 emp.csv 和 dept.csv 文件到虚拟机。
基于外部数据源 emp.csv 创建 RDD,再采用 RDD.toDF()将它转为 DataFrame。要求:
- (1)并使用 schema 为 StructType 的方式。
- (2)输出DataFrame.collect()的内容。
- (3)输出DataFrame.printSchema()的内容。
- 基于外部数据源 dept.csv 创建RDD,再采用 spark 的 createDataFrame() 将它转为 DataFrame。要求:
- (1)schema 为"fieldName:fieldType"的方式。
- (2)输出DataFrame.collect()的内容。
- (3)输出DataFrame.printSchema()的内容。
【实验名称】 实验5.3:部署 Spark 访问 Hive 数据
【实验目的】
掌握Spark 访问 Hive 数据的部署方法
【实验环境】
- 操作系统:Ubuntu 16.04
- Spark 2.x
- Hive 2.x
- Hadoop 2.7.3
- PyCharm 或 Jupyter Notebook
【实验资源】
数据下载:
https://pan.baidu.com/s/1kXZ-bMTMXA1A3rszHebMBA#提取码t7q1
【实验原理】
通过配置 Spark,让 Spark 可以访问 Hive 的数据和使用 SparkSession.sql() 函数查询 DataFrame 数据。
通过把 Hadoop 的 core-site.xml 和 hdfs-site.xml,和 Hive 的配置文件 hive-site.xml 复制到 SPARK_HOME/conf 目录下。
【Hive优化参数配置和解决常见问题】
- 解决
Unable to instantiate org.apache.hadoop.hive.ql.metadata.SessionHiveMetaStoreClient问题。
这通常是由于 Hive 的 MetaStore Server校验 Schema 出错导致的。只需要关闭校验选项即可。找到Hive安装目录/conf/hive-site.xml,增加以下选项配置。
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
</property>
- 优化 Hive 执行卡顿的参数配置。启动 Hive 以后,可以在 Hive 终端执行以下参数设置,优化运行效率。
#100%执行完 map 再执行 reduce,避免运行 map 同时又运行 reduce,占用太多资源。
hive>set mapreduce.job.reduce.slowstart.completedmaps=1.0;
# 设置 mapreduce 执行内存为 2048MB,可视虚拟机资源情况自行调整。
hive>set mapreduce.map.memory.mb=2048;
# 设置 mapreduce CPU 执行核数为2,可视虚拟机资源情况自行调整。
hive>set mapreduce.map.cpu.vcores=2;
- 使用 Hive 日志进行错误诊断。
Hive 的日志默认是在/tmp/{用户名}/hive.log。如果是使用Node0虚拟机镜像的Hadoop用户,则是在/tmp/hadoop/hive.log。
如果需要调整 hive 的日志路径,可以在Hive安装目录/conf/下修改日志配置。
cp hive-exec-log4j2.properties.template hive-exec-log4j2.properties
vim hive-exec-log4j2.properties
修改property.hive.log.dir选项
#property.hive.log.dir = ${sys:java.io.tmpdir}/${sys:user.name}
property.hive.log.dir = /opt/hive/logs
【实验步骤】
- 把 Hadoop 的 core-site.xml 和 hdfs-site.xml,和 Hive 的配置文件 hive-site.xml 复制到 SPARK_HOME/conf 目录下。
cp $HIVE_HOME/conf/hive-site.xml $SPARK_HOME/conf
cp $HADOOP_HOME/etc/hadoop/core-site.xml $SPARK_HOME/conf
cp $HADOOP_HOME/etc/hadoop/hdfs-site.xml $SPARK_HOME/conf
- 打开 SPARK_HOME/conf 目录,查看三个配置文件是否复制成功。
ls $SPARK_HOME/conf
注意,如果hive-site.xml内配置的 MySQL 链接如果是jdbc:mysql://localhost:3306/hive?useSSL=false,则要确保/etc/hosts下配置 localhost 指向 127.0.0.1。
sudo vim /etc/hosts
#确保有以下2条,没有则补充
127.0.0.1 localhost
127.0.0.1 node0
- 请从以下链接下载
dept.csv,并上传到HDFS 根目录下。过程略。
https://pan.baidu.com/s/1kXZ-bMTMXA1A3rszHebMBA #提取码t7q1
- 启动 hadoop 和 hive。
start-hdp.sh
hive
- 使用 Hive 创建数据库
hive> create database spark;
hive> use spark;
- 导入
dept.csv为表dept001。请替换001为你的学号后三位。
hive> create table spark.dept001 (deptno INT, name string, location string) COMMENT 'dept001' ROW FORMAT DELIMITED FIELDS TERMINATED BY ',';
hive> load data inpath '/dept.csv' into table dept001;
- 使用 Hive 查询
dept001。请替换001为你的学号后三位。
hive> select * from dept001;
- 退出
Hive,启动spark和pyspark。
start-spark.sh
pyspark --master spark://node0:7077 --jars /opt/hive/lib/mysql-connector-java-5.1.48.jar
- 测试能够在 Spark 调用 Hive 的数据。请替换001为你的学号后三位。
spark.sql('select * from spark.dept001 limit 1').show()
【实验名称】 实验5.4:使用DataFrame分析出租车的 GPS 信息
【实验目的】
掌握DataFrame的常用操作
【实验环境】
- 操作系统:Ubuntu 16.04
- Spark2.x
- PyCharm 或 Jupyter Notebook
【实验原理】
使用 Spark DataFrame 对 csv 数据进行查询
【实验资源】
请从以下链接下载某地区出租车 GPS 定位数据taxi.csv。
https://pan.baidu.com/s/1kXZ-bMTMXA1A3rszHebMBA#提取码t7q1
部分数据见下图:
| 编号(id) | 纬度(lat) | 经度(lon) | 时间戳(time) |
|---|---|---|---|
| 1 | 30.624806 | 104.136604 | 211846 |
| 1 | 30.624809 | 104.136612 | 211815 |
| 1 | 30.624811 | 104.136587 | 212017 |
| 1 | 30.624811 | 104.136596 | 211916 |
| 1 | 30.624811 | 104.136619 | 211744 |
【实验要求】
根据上述条件,结合课堂上学习的“DataFrame的常用操作”相关知识,编写代码实现如下要求,请把在实验报告记录你的思考过程,完整代码和实验结果。
- (1)查询编号为 5 的出租车的 GPS 数据的前 10 行。
- (2)统计出租车的总数有多少。
- (3)统计出租车id为297的 GPS 点记录有多少条。
【实验名称】 实验5.5:使用SparkSQL分析图书信息
【实验目的】
掌握SparkSQL的常用操作
【实验原理】
请从以下链接下载图书数据book.txt
https://pan.baidu.com/s/1kXZ-bMTMXA1A3rszHebMBA #提取码t7q1
数据内容举例如下:
| seq(序号) | name(书名) | rating(评分) | price(价格) | pub(出版社) | url |
|---|---|---|---|---|---|
| 40332 | 简爱 | 8.8 | 29.80元 | 上海世界图书出版公司 | https://book.douban.com/subject/ |
【实验环境】
- 操作系统:Ubuntu 16.04
- Spark2.x
- PyCharm 或 Jupyter Notebook
【实验要求】
根据上述条件,结合课堂上学习的 Spark SQL 相关知识,编写代码实现如下要求,请把在实验报告记录你的思考过程,完整代码和实验结果。
(1)创建RDD,并将RDD转为DataFrame。
(2)调用 createOrReplaceTempView,创建临时视图名为
book001,注意替换001为你的学号后三位。(3)使用 SQL 语句查询前10条数据。
(4)统计书名包含“微积分”的书的数量
(5)查询评分大于等于9分,小于等于9.5分,且书名包含“艺术”的书,只展示前10条的序号、书名和评分,按分数从高到低排列。
(6)计算所有书名包含“艺术”的评分平均值
(7)统计出版书数量最大的出版社前10名,按数量从高到低排列。
【实验名称】 实验5.6:DataFrame的保存和加载
【实验目的】
掌握DataFrame的保存和加载
【实验原理】
parquet文件的加载示例:
userDF = spark.read.load("/home/hadoop/users.parquet")
json文件的加载示例:
peopleDF = spark.read.json("/home/hadoop/people.json")
peopleDF = spark.read.format("json").load("/home/hadoop/people.json")
保存到parquet文件示例:
userDF.select("name","favorite_color").write.save("/home/hadoop/result1")
userDF.select("name","favorite_color").write.mode("overwrite").save("/home/hadoop/result1")
保存到csv文件示例:
userDF.select("name","favorite_color").write.format("csv").save("/home/hadoop/result2")
userDF.select("name","favorite_color").write.csv("/home/hadoop/temp/result3")
【实验环境】
- 操作系统:Ubuntu 16.04
- Spark:Spark2.x
- pyspark
【实验步骤】
统计每个出版社评分最高的书,展示书的序号,名称,评分和出版社。并且按照评分从高到低排列。保存结果到
/home/hadoop/pub-best001目录。注意替换001为你的学号后三位。加载步骤1生成的 CSV 文件,并且筛选书名含有“艺术”2字的,评分最高的10本书,按按照评分从高到低排列。
提示:从 CSV 读取数据需要重新配置 Schema。
【常见问题解答FAQ】
问题1:使用 Spark SQL 的时候频繁遇到 Py4j 的Connection error 或者 JVM 提示Cannot allocate memory错误。
答:这些问题一般都是由于虚拟机的内存不足导致的。可以使用free -m命令查看虚拟机内存使用状况。
# free 代表系统当前还剩余的内存(单位MB)。
total used free shared buff/cache available
Mem: 1838 350 1113
如果内存剩余量不足100M,可能就会导致上面的问题。
解决内存不足的问题可以:
(1)关闭虚拟机,右键点击镜像,选择设置,调整内存大小。
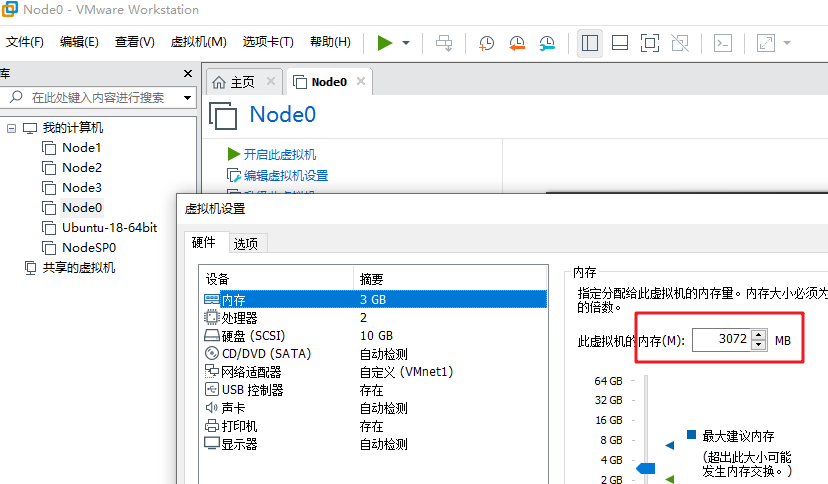
(2)关闭不使用的服务,例如 yarn,hive 都可以退出。
(3)如果你的电脑内存资源很紧张,可以考虑开启 swap 分区,相当于使用硬盘空间作为虚拟内存。虚拟机free -m命令显示 swap 的total 为0,则表示swap分区没有开启,开启命令如下:
- 创建 swap 文件
#这里count的数值就是 swap 分区的大小,单位为MB
sudo dd if=/dev/zero of=/swapfile count=2048 bs=1M
- 激活 swapfile
sudo chmod 600 /swapfile
sudo mkswap /swapfile
#如果运行成功会显示
#Setting up swapspace version 1, size = 2097148 KiB
#no label, UUID=...
- 开启 swap
sudo swapon /swapfile
#查看 swap 的 total 值是否是你配置的大小
free -m
- 添加 Swap 自动开启的配置。
sudo vim /etc/fstab
#文件最后一行加上
/swapfile none swap sw 0 0
问题2:提示连接不上 HDFS,Call From node0/127.0.0.1 to node0:8020 failed on connection exception。
答:可能是由于node0没有配置对应的IP,导致连接不上HDFS。请保证 hosts 的配置包含以下2行。sudo vim /etc/hosts
127.0.0.1 node0
127.0.0.1 localhost
问题3:提示“The specified datastore driver (“com.mysql.jdbc.Driver”) was not found in the CLASSPATH.”
答:这是由于 PySpark 没有找到 MySQL 驱动,导致无法连接上 Hive 的 MySQL。请使用以下命令启动PySpark。
pyspark --master spark://node0:7077 --jars /opt/hive/lib/mysql-connector-java-5.1.48.jar
问题4:提示“o25.sql:…Uable to instantiate org.apache.hadoop.hive.ql.metadata.SessionHiveMetaStoreClient;”
答:这个问题可能原因:
(1)hosts配置不正确导致无法连接 MySQL。请参考问题2解决方法。
(2)PySpark 没有找到 MySQL 的 JDBC 驱动。请参考问题3解决方法。
