【版本】
当前版本号v20250326
| 版本 | 修改说明 |
|---|---|
| v20250326 | 修正部分命令错误 |
| v20250213 | 初始化版本 |
任务3.1 - 编写 MapReduce wordcount 程序
【任务目的】
- 掌握 MapReduce 程序编写要领
【任务环境】
- Windows 7 以上64位操作系统
- JDK8
- IDEA
- Hadoop 3
- Maven 3
【任务资源】
- countryroad.txt
【任务内容】
- 编写 MapReduce wordcount 程序
【任务步骤】
打开 Part 4 的 hadoopexp 项目。
在项目
hadoop-exp\src\main\java下创建一个名为hadoop+你学号后4位.mapreduce.wc的包。注意替换为你的学号后4位。在包下面新建一个
WordCountMapper的类。代码如下,注意替换为你的学号后4位。
package hadoop你的学号后4位.mapreduce.wc;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable>{
@Override
protected void map(LongWritable key1,Text v1,Context context)
throws IOException,InterruptedException{
String data=v1.toString();
// 分词
String[] words=data.split(" ");
// 输出 k2 v2
for(String w:words){
context.write(new Text(w),new IntWritable(1));
}
}
}
- 在包下面新建一个
WordCountReducer的类。代码如下,注意替换为你的学号后4位。
package hadoop你的学号后4位.mapreduce.wc;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
@Override
protected void reduce(Text k3, Iterable<IntWritable> v3,Context context) throws IOException, InterruptedException {
//context 是 reduce 的上下文
// 对 v3 求和
int total = 0;
for(IntWritable v:v3){
total += v.get();
}
// 输出: k4 单词 v4 频率
context.write(k3, new IntWritable(total));
}
}
- 在包下面新建一个
WordCountMain的类。代码如下,注意替换为你的学号后4位。
package hadoop你的学号后4位.mapreduce.wc;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
import java.io.IOException;
public class WordCountMain {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
int argLength=otherArgs.length;
if (otherArgs.length < 2) {
System.err.println("Usage: wordcount <in> [<in>...] <out>");
System.exit(2);
}
//获取一个作业实例,名称为Word Count
Job job=Job.getInstance(conf,"Word Count");
//设置运行的jar包里的类
job.setJarByClass(WordCountMain.class);
//设置Mapper
job.setMapperClass(WordCountMapper.class);
//设置Reducer
job.setReducerClass(WordCountReducer.class);
//设置Combiner
job.setCombinerClass(WordCountReducer.class);
//设置k4类型
job.setOutputKeyClass(Text.class);
//设置v4类型
job.setOutputValueClass(IntWritable.class);
//可以接受多个参数作为输入文件路径
for(int i=0;i<argLength-1;i++) {
FileInputFormat.addInputPath(job, new Path(otherArgs[i]));
}
//最后的一个参数是结果输出路径
FileOutputFormat.setOutputPath(job,new Path(otherArgs[argLength-1]));
//如果作业运行成功就成功退出
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
- 修改项目的
pom.xml。其中<mainClass>标签内的类修改为WordCountMain类的包内路径。参考代码如下,注意替换为你的学号后4位。
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-jar-plugin</artifactId>
<version>3.2.0</version>
<configuration>
<archive>
<!--<manifestFile>${project.build.outputDirectory}/META-INF/MANIFEST.MF</manifestFile>-->
<manifest>
<!-- main()所在的类,注意修改 -->
<mainClass>hadoop你的学号后4位.mapreduce.wc.WordCountMain</mainClass>
</manifest>
</archive>
</configuration>
</plugin>
</plugins>
</build>
- 在 IDEA 的左下角找到 Terminal,输入以下命令,使用 Maven 对代码进行打包。

mvn compile package -Dmaven.test.skip=true
生成的 jar 包会在项目的 target 目录下。名称为
hadoop-exp-1.0.jar。把
hadoop-exp-1.0.jar和countryroad.txt都上传到NodeA的/home/hadoop目录下。在
NodeA启动Hadoop.
start-hdp.sh
- 把
NodeA本地的countryroad.txt文件上传到 HDFS 的根目录/。
hdfs dfs -put /home/hadoop/countryroad.txt /
- 在
NodeA上执行以下命令,开始运行我们编写的 Wordcount 程序。
hadoop jar /home/hadoop/hadoop-exp-1.0.jar /countryroad.txt /output6
- 运行成功以后,查看结果。
hdfs dfs -cat /output6/part-r-00000
任务3.2 - 编写 MapReduce 程序统计数据
【任务目的】
- 掌握编写 MapReduce 程序进行统计数据
【任务环境】
- Windows 7 以上64位操作系统
- JDK8
- IDEA
- Hadoop 3
- CentOS 7
- Maven 3
【任务资源】
- sales.csv
下载链接:https://pan.baidu.com/s/1ghde86wcK6pwg1fdSSWg0w
提取码:v3wv
【任务内容】
- 编写 MapReduce 程序进行数据统计
【任务要求】
(1)获取
sales.csv文件,文件内是一份销售数据,数据描述如下: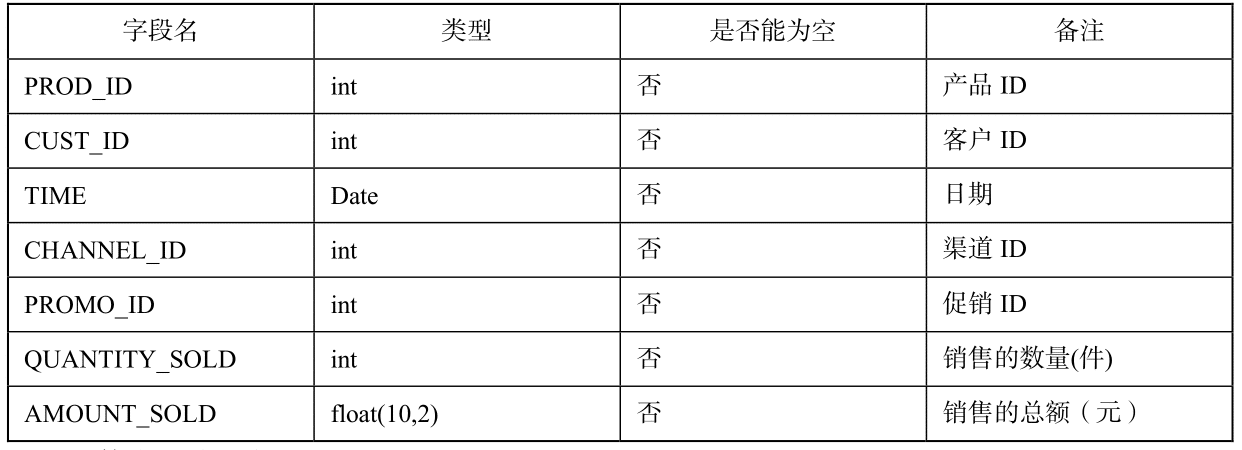
(2)根据以上实验步骤,编写相关代码,调用MapReduce,求出各年销售总额。
【任务步骤】
打开 Part 4 的 hadoopexp 项目。
在项目
hadoop-exp\src\main\java下创建一个名为hadoop+你学号后4位.mapreduce.sales的包。注意替换为你的学号后4位。在包下面新建一个
SalesMapper的类。下面是部分参考代码,请完成关键的编码部分,注意替换为你的学号后4位。
package hadoop你的学号后4位.mapreduce.sales;
import org.apache.hadoop.io.*;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class SalesMapper extends Mapper<LongWritable, Text, Text, DoubleWritable>{
@Override
protected void map(LongWritable key1,Text v1,Context context)
throws IOException,InterruptedException{
String data=v1.toString();
// 分词
String[] words=data.split(",");
// 输出 k2 v2
此处关键代码请自己完成
}
}
- 在包下面新建一个
SalesReducer的类。代码如下,注意替换为你的学号后4位。
package hadoop你的学号后4位.mapreduce.sales;
import org.apache.hadoop.io.DoubleWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class SalesReducer extends Reducer<Text, DoubleWritable, Text, DoubleWritable> {
@Override
protected void reduce(Text k3, Iterable<DoubleWritable> v3,Context context) throws IOException, InterruptedException {
此处关键代码请自己完成
}
}
- 在包下面新建一个
SalesMain的类。代码如下,注意替换为你的学号后4位。
package hadoop你的学号后4位.mapreduce.sales;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.DoubleWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
import java.io.IOException;
public class SalesMain {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
int argLength=otherArgs.length;
if (otherArgs.length < 2) {
System.err.println("Usage: xxx.jar <in> [<in>...] <out>");
System.exit(2);
}
//获取一个作业实例
Job job=Job.getInstance(conf,"Sales Statistic");
//设置运行的jar包里的类
job.setJarByClass(SalesMain.class);
//设置Mapper
job.setMapperClass(SalesMapper.class);
//设置Reducer
job.setReducerClass(SalesReducer.class);
//设置Combiner
job.setCombinerClass(SalesReducer.class);
//设置k4类型
job.setOutputKeyClass(Text.class);
//设置v4类型
job.setOutputValueClass(DoubleWritable.class);
//可以接受多个参数作为输入文件路径
for(int i=0;i<argLength-1;i++) {
FileInputFormat.addInputPath(job, new Path(otherArgs[i]));
}
//最后的一个参数是结果输出路径
FileOutputFormat.setOutputPath(job,new Path(otherArgs[argLength-1]));
//如果作业运行成功就成功退出
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
- 修改项目的
pom.xml。其中<mainClass>标签内的类修改为SalesMain类的包内路径。参考代码如下,注意替换为你的学号后4位。
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-jar-plugin</artifactId>
<version>3.2.0</version>
<configuration>
<archive>
<!--<manifestFile>${project.build.outputDirectory}/META-INF/MANIFEST.MF</manifestFile>-->
<manifest>
<!-- main()所在的类,注意修改 -->
<mainClass>hadoop你的学号后4位.mapreduce.sales.SalesMain</mainClass>
</manifest>
</archive>
</configuration>
</plugin>
</plugins>
</build>
- 参考实验6.1 打包、上传包、运行和查看结果的步骤。参考结果如下:
1998 2.408391494998411E7
1999 2.221994766001435E7
2000 2.37655066200018E7
2001 2.8136461979984347E7
##【常见问题】
1. IDEA在命令行运行打包命令出错。
答:这是因为 IDEA 某些新版本使用powershell 作为默认命令行,以下命令会出错。
mvn compile package -Dmaven.test.skip=true
- 换为以下命令执行即可。
mvn compile package '-Dmaven.test.skip=true'
